
In this runtime field example repository you can find a list of possible runtime fields used in the Elastic Stack to ease the setup of new data sources. Elastic runtime fields are a great way to solve a couple of challenges you may run into if you are new to Elasticsearch. They were introduced in v7.11. You can read more about the intention in this blog article.
What is a runtime field in the Elastic Stack?
Runtime fields enable you to create and query fields that are evaluated only at query time. Instead of indexing all the fields in your data as it’s ingested, you can pick and choose which fields are indexed and which ones are calculated only at runtime as you execute your queries. Runtime fields support new use cases and you won’t have to reindex any of your data. Adapt to changing log file formats, query new fields that were not indexed at ingest time, fix errors in index mappings, or iterate on the preparation and perfection of indices over time.
Many of our prebuilt Kibana dashboards are using these runtime fields as well to improve the usability and accessibility.
How to add a runtime field in Kibana
The examples in this Elastic runtime field example repository just showing the painless script that is necessary to do the desired task. In Kibana you can add a runtime field using many different ways. The most easy ones are in Discover, Lens and Index pattern management. All of these option finally adding the runtime field to index pattern in Kibana. The runtime fields that are defined in the index pattern only existing during query execution time in Kibana. If you use e.g. external scripts these fields are not available.
To make runtime fields also available in external scripts and reindex jobs you need to add them to the mapping of your index directly using Kibana Dev Tools or Index Templates.
In Discover
In the Discover App of Kibana you can add a runtime field using the button next to the index pattern chooser. Just click on “Add field to index pattern” to add a new field.
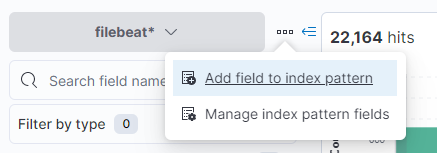
After clicking on that you will see a new Sidebar. To add a runtime field you need to activate “Set value”. All the scripts that we provide in this repository can be copy pasted into the “Define script” section.
In Lens Editor
In the Lens Visualization editor you also have the possibility to add a runtime field to your index pattern. You can follow the same way as in Discover.
In Index pattern management
In the Index pattern management in Kibana you can also change your existing runtime fields. In v.7.14 there is no way to filter for runtime fields. So you need to know the name you provided to find your runtime field. When clicking on edit you get back to the sidebar and can change your runtime field. To see the result of that change in Discover or Lens you need to fully refresh the page to load the new definition.
Emit function and parameter overview
Each runtime fields needs to call emit() . The emit() function is used to populate the value to the runtime field. The input for the emit function changes for the different types of fields that you can emit.

Access the message field from log integrations
Many of the out of the box integrations that elastic is offering sending their data in the message field. The message field is therefore designed to make full text search as fast and relevant as possible. In order to achieve that some field functions are deactivated, which can lead into issues using runtime fields.
Some of the error message you might see are
- match_only_text fields do not support sorting and aggregations
- accessing data within the inverted index is not allowed
If you are facing this issues and don’t want to change the mapping that is given by Elastic but still want to use runtime field grok and regex features you need to access the _source field directly.
The examples below always use doc[“message”].value to get the data from the field. However in order to access the _source directly you can also use params._source.message instead. This will be a bit slower but prevents you from changing the mapping of the message field.
Available runtime field examples
Use this Elastic runtime field example to emit a static value into a new field. Using static values can be very important to make the use of dashboards more intuitive for the users of the dashboard. If a user is filtering for a specific value of a field this field and value needs to exists in any index that is used in that dashboard. Usually that happens automatically if you use the Elastic Common Schema.
If you added data sources to your dashboard that do not contain all data from the elastic common schema this could lead into problems when filtering the Kibana dashboard. Using the runtime field that emits a static value or the value from another field can help to solve that.
Here is the example for that runtime field:
emit("my value");The emit method emits the value that it gets in the field. This example emits just a static string value.
Copying a value from a field to another field can be an important use case to make dashboards working smooth. Per default Kibana dashboards filtering every visualization when a new filter is set. In some cases you want to have a general filter for the full dashboard.
Lets say you’ve build a dashboard that is only relevant for one of your observed APM services. You could build in the filter for the desired service into every single visualization or as a general filter in the dashboard. However if you build it as a general filter you need to set the service name for all visualizations in the same field. Same holds for e.g. IP addresses, host names and other fields that contain important data. Copy the value from one indexed field into a new runtime field can be good option to solve that issue.
Another important use case for this kind of Elastic runtime field is to change the mapping of one field without reindexing. Let’s say you indexed a field as text that you would like to use as a keyword field. Before we had runtime fields you had to reindex the data and make the mapping right. Using runtime fields you can just copy the value and use new keyword mapping to achieve the same result.
Here is the null safe example code for a runtime field that can copy the value from one source field to the new runtime field.
if (doc.containsKey('source.field.name')) {
def source = doc['source.field.name'].value;
if (source != "") {
emit(source);
}
}The first if is checking that the field exists in every document. This is important if you have documents with different fields. Especially if the source field is not existing in every document of your source indices. The second if is checking that there is a value in the field. Most likely you don’t want to populate a new field when the source is empty.
The above example does not work if you want to copy a geo_point value. In order to do that the emit function needs to have to parameters. The following example shows a runtime field that is using a geo_point field that was wrongly mapped as text and keyword. The target of the copy to another field runtime field is to change the mapping to geo_point again.
if (doc.containsKey('enriched.location.keyword')) {
def source = doc['enriched.location.keyword'].value;
def geo_point = source.splitOnToken(",");
if (source != "") {
def lat = Double.parseDouble(geo_point[0]);
def lon = Double.parseDouble(geo_point[1]);
emit(lat,lon);
}
}The Elasticsearch query DSL is very powerful to search for anything you like. You can search for concrete keyword, for phrases, for ranges of values, IPs and times and much more. But there are also some things in comparison to a SQL based query that are not so easy in Elasticsearch or Kibana Query Language. One of these challenging search features is to look for documents that have the same value in two different fields. Therefore you need the ability to compare two field values.
Comparing two field values can not be done in any of the query languages that Elastic supports. However using a runtime field you can achieve this. The concept is to compare the values using the runtime field and in the query you only search for the result of the runtime field.
emit (doc['source.host.name'].value == doc['dest.host.name'].value);This is a simple comparison of two field values. You may need to check the existence of both fields before doing the comparison. Otherwise you might run into shard failures on execution.
Combining two field values can be done as easy as comparing two field values. The only difference is that you have both values together in one field. You may want to store Surname and Lastname in your index. Storing the complete name in a separate field would require extra storage. Using runtime fields to simply calculate the concatenation is a good way to save storage and achieve the same result.
Another use case for combining the values of two fields into one field is to build the query string for an external application. Lets say you would like to use multiple values of your document to e.g. jump into a virustotal analysis of your data. For doing that Kibana offers the ability to format fields that contain strings as URL. Doing that the user of Kibana is able to click on the field value.
This examples shows the combination of lat and lon values into a single field:
emit (doc['geo.dest.keyword'].value + ':' + doc['geo.src.keyword'].value);Another important use case for concatenate two fields is to add multiple field values to the GET parameters of your target URL. Its also fine to only use a value from field. In that case the runtime field helps because you have a dedicated field for the link to the 3rd party system.
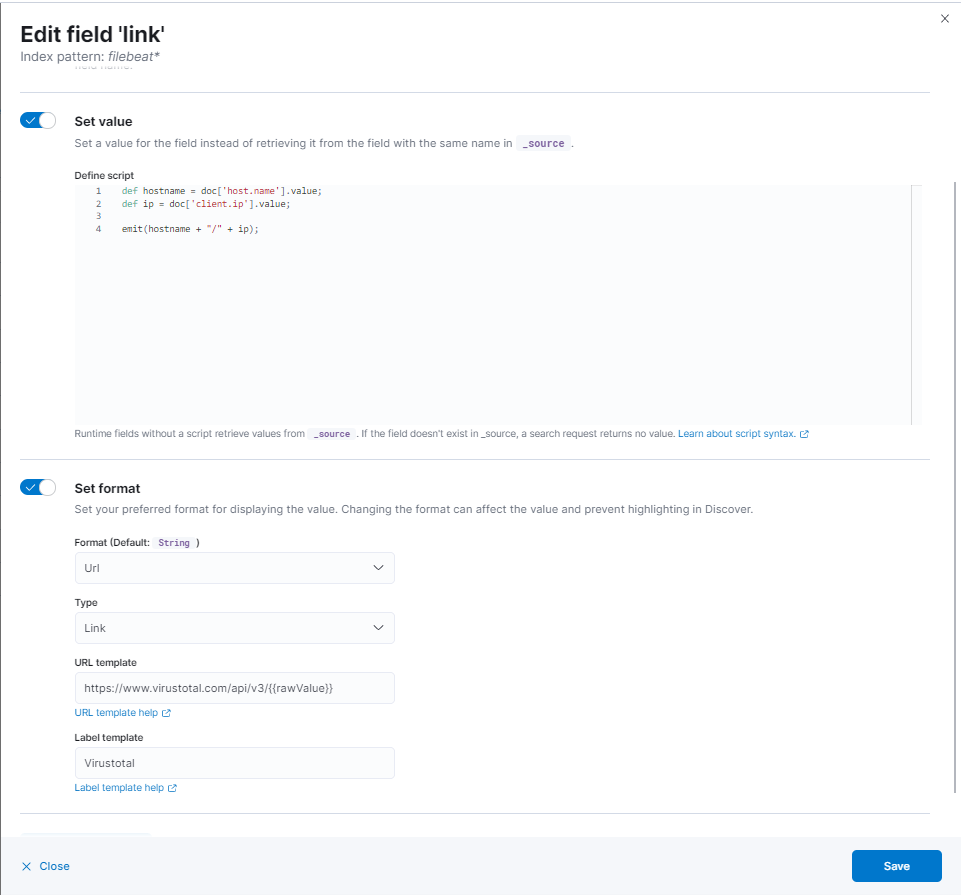
def hostname = doc['host.name'].value;
def ip = doc['client.ip'].value;
emit(hostname + "/" + ip);Using regex in a runtime field can be very useful to get specific text within your source field and use it as value for your target runtime field. In most cases you will do this to extract a specific substring and use this as a keyword for your visualizations in Kibana. While this makes a lot of sense you need to be careful using Regex in a runtime field. The regex expressions can get very heavy to compute. This can reduce the performance significantly.
Remember that all the regex expression in a runtime will get executed for every document while querying. Elastic also allows to use dissect and grok patterns in runtime fields. Both are good alternatives in comparison to use plain regex. Using the regex pattern should be always the last option to choose.
If you want to execute a regex on a field that is mapped as text you need to follow these guidelines to make this available. However the conclusion is that you should always use keyword fields instead of text fields for the regex extraction.
def fieldname = "host.name";
if (!doc.containsKey(fieldname)) {
return
}
def m = /([A-Za-z0-9]+)/.matcher(doc[fieldname].value);
if ( m.matches() ) {
emit (m.group(1))
}The first part is checking that the target field name exists. If you want to regex in a sparse field this prevents shard failures on search execution. The second part is defining the regex pattern and the field to extract to values from. If you use more complex regex scripts you may also need to change the parameter of m.group() as this is defining which part of the regex match should get emitted.
For a simple check that a regex pattern is present in longer string you can also use this shorthanded syntax.
if (doc['host.name'].value =~ /([A-Za-z0-9]+)/) {
emit("value detected");
} else {
emit ("value not detected");
}… or even shorter if you use the Boolean result of the comparison directly. Make sure to set the format of the field to Boolean.
emit (doc['host.name'].value =~ /([A-Za-z0-9]+)/)Using grok in a runtime field can be very powerful. The Grok pattern is already widely used in the Elastic Stack. You can use Grok in your Logstash pipelines as well as in Ingest Node Pipelines of Elasticsearch. Grok is a simplified and improved way to apply regular expressions (Regex) on top of your fields. While there is also the possibility to use Regex pattern directly using runtime fields it has a lot of advantages to use a grok runtime field.
With Grok you have the ability to use the prebuilt Regex patterns as well as creating your own. To create your own Grok patterns it is good practice to use the Kibana Grok Debugger. Of course you can also use a third party Grok Debugger.
In the Elastic documentation you can find the following example. This runtime field example is parsing the message field that may contains an Apache Log. If this is the case it extracts the client IP. In v.7.14 it is not possible to extract multiple results from grok into different fields.
String clientip=grok('%{COMMONAPACHELOG}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip);This is an example that is using a prebuilt grok pattern to extract the domain from the referrer. This is based on Elastic APM Real user monitoring data. While the first example is doing basic null checks this example is more resilient and is not producing shard failures while searching. This example also emits the field with empty value if there is no page referrer.
if (doc['transaction.page.referer'].size()>0) {
def referer_full = doc["transaction.page.referer"].value;
if (referer_full != null) {
String domain=grok('https?://(www.)?%{HOSTNAME:domain}').extract(referer_full)?.domain;
if (domain != null) emit(domain);
return;
}
}
emit("");in theory you can built every grok parsing using a runtime field. But you should always consider the performance impact. If you need to field for a long time it is good practice to do the parsing on ingest time using ingest node pipelines. This will increase your search performance significantly in comparison to use runtime fields. However if you wanna test a field first or if you don’t want to reindex your data using a runtime field for grok is a very useful option.
Another example is accessing the message field directly from _source.
String clientip=grok('Returning %{NUMBER:foobar} ads').extract(params._source.message)?.foobar;
emit(clientip);Using dissect in a runtime field is another simplification of using the Grok filter. While in grok you can have any type of delimiter between the different field using dissect you always have the same.
The Dissect operation is like a split operation. While a regular split operation has one delimiter for the whole string, this operation applies a set of delimiters to a string value.
Dissect does not use regular expressions and is very fast. Thatswhy its also not influencing the performance of your search that much. However, if the structure of your text varies between documents then Grok is more suitable.
There is a hybrid case where Dissect can be used to de-structure the section of the line that is reliably repeated and then Grok can be used on the remaining field values with more regex predictability and less overall work to do.
The dissect operation is like grok already well known using Logstash pipelines (filter plugin) or ingest nodes pipelines. Now as it is available also as a painless operation it simplifies a lot of use cases.
This runtime field example from the Elastic documentation uses the dissect filter to also parse Apache Log lines. It does the same as the example in the Grok section, but typically it is much faster using dissect.
String clientip=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{status} %{size}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip);Dissect can be used to extract multiple data fields at once. This also works with runtime fields as the emit function is also able to take a map of fields as input parameter. This type of extraction and field generation can of course also be used for other use cases.
Map fields=dissect('%{source.ip} %{url.domain} - %{client.id} %{port} [%{@timestamp}]').extract(params["_source"]["message"]);
emit(fields);Manipulating the time can be very useful for many different use cases. You can improve your visualizations and insides into your data by calculating the hour-of-day or the day-of-week. Manipulate time painless features could be also usedd to influence the timestamp itself for improved timezone management or fixing time shift issues. Another important use case is to calculate the duration between two different timestamps. Lets say you have a timestamp for log creation and another for the creation of the document in Elasticsearch. Knowing the duration between those two events can help to identify issues in your ingest pipelines. For all of this use cases you can use also runtime fields. The main advantage is that you can test your new field on the fly also with older data.
Using the painless scripting language to calculate your runtime fields provides a lot of possibilities and power to manipulate and work with the time.
The following example calculates the day of week. So you get Monday, Tuesday and so on as a result in your runtime field. This can be very nice to use in visualizations and learn more about the usage patterns e.g. analysing access logs or real user monitoring data.
emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))The following example calculates the hour of day. Your runtime field will have values from 00 to 24. This is a great way to aggregate your data and learn more about the usage pattern. Our real user monitoring dashboard is using both day of week and hour of day to show when the users typically accessing the web application.
ZonedDateTime date = doc['@timestamp'].value;
int hour = date.getHour();
if (hour < 10) {
emit ('0' + String.valueOf(hour));
} else {
emit (String.valueOf(hour));
}The following example is showing how to check the age of an specific document. It is getting the current date and also takes the date of the @timestamp field. This can also be used to calculate durations or to calculate how “old” the document is. All of that can be valid use cases to visualize in Kibana dashboards.
long nowDate = new Date().getTime();
long docDate = doc['@timestamp'].value.toEpochMilli();
long difference = nowDate - docDate;
boolean isOlderThan24hr = false;
if (difference > 86400000) {
isOlderThan24hr = true;
}
emit(isOlderThan24hr);In this section we show runtime field examples that has been submitted by other users. Getting input from the Elastic Community is a great help. It enables Elasticsearch users all around the world to solve their needs more quickly. Thanks for all contributions that have been made.
Elastic Runtime field examples from Leaf
index_stats.index_date
This useful to extract all indices or data stream and find out the date of the index. This is useful for aggregating data usage.
if (doc['index_stats.index'].size() != 0) {
def index_name = doc['index_stats.index'].value;
if (index_name !=null) {
if (index_name =~ /[12][0-9]{3}./) { // match year pattern like 1903, 2021
Map my=grok('(%{GREEDYDATA:pattern}-%{INT:year}\\.%{INT:month}\\.%{INT:day})|(%{GREEDYDATA:pattern}-%{INT:year}\\.%{INT:month}\\.%{INT:day}-%{GREEDYDATA:junk})|(%{GREEDYDATA:pattern}-%{INT:year}-%{INT:month}-%{INT:day})').extract(index_name);
if (my !=null) {
emit(my.year+"."+my.month+"."+my.day);
}
}
}
}
index_stats.index_pattern
This useful to extract all indices or data stream and find out the index pattern the index. This is useful for aggregating data usage.
if (doc['index_stats.index'].size() != 0){
def index_name = doc['index_stats.index'].value;
if (index_name !=null) {
if (index_name =~ /[12][0-9]{3}./) { // match year pattern like 1903, 2021
Map my=grok('(%{GREEDYDATA:pattern}-%{INT:year}\\.%{INT:month}\\.%{INT:day})|(%{GREEDYDATA:pattern}-%{INT:year}\\.%{INT:month}\\.%{INT:day}-%{GREEDYDATA:junk2})|(%{GREEDYDATA:pattern}-%{INT:year}-%{INT:month}-%{INT:day})').extract(index_name);
if (my !=null){
emit(my.pattern);
}
}
} else {
emit(index_name);
}
}logger.category
You can use this to extract logger from applications to aggregate data in higher hierarchical level.
if (doc['logger.keyword'].size() != 0){
def fullname = doc['logger.keyword'].value;
def xpack="org.elasticsearch.xpack";
def http="org.elasticsearch.http";
def org="org.elasticsearch";
if (fullname !=null){
if (fullname =~ /org.elasticsearch.http/) {
def prefix = fullname.substring(http.length()+1);
int firstDotIndex = prefix.indexOf('.');
emit(prefix.substring(0,firstDotIndex));
}
else if (fullname =~ /org.elasticsearch.xpack/) {
def prefix = fullname.substring(xpack.length()+1);
int firstDotIndex = prefix.indexOf('.');
emit(prefix.substring(0,firstDotIndex));
}
else if (fullname =~ /org.elasticsearch/) {
def prefix = fullname.substring(org.length()+1);
int firstDotIndex = prefix.indexOf('.');
emit(prefix.substring(0,firstDotIndex));
}
}
}
version_for_sorting
This is because traditionally we have x.y.z as version number which is not sortable (where it treat as numerical sorting, so the order becomes 7.1.0, 7.10.1, 7.2.0 etc) and not queryable. One cannot say I want to check versions greater than x.y.z . But with 0x0y0z model, it can achieve both.
If you have permission to modify mapping of the index, you should change it to version type, then there will be no need to use runtime field here.
if (doc['version.keyword'].size() != 0){
def version = doc['version.keyword'].value;
if (version !=null){
int firstDot = version.indexOf('.');
int secondDot = version.indexOf('.', firstDot+1);
def major = version.substring(0,firstDot);
def minor = version.substring(firstDot+1,secondDot);
def patch = version.substring(secondDot+1);
while (major.length() < 2){
major="0"+major
}
while (minor.length() < 2){
minor="0"+minor
}
while (patch.length() < 2){
patch="0"+patch
}
emit(major+minor+patch);
}
}Elastic Runtime field examples from Graham
Sorted day of week
A day of the week that’s sortable in visualizations. This is an extension to the date math group of runtime fields. More date masks can be found in the Java docs.
ZonedDateTime input = doc['timestamp'].value;
String output = input.format(DateTimeFormatter.ofPattern('e')) + ' ' + input.format(DateTimeFormatter.ofPattern('E'));
emit(output);Return a static value when a condition is met
This runtime field can be useful for integrating event style information into visualizations. The example is using “record_score” from ML Anomalies to only show the anomalies over a certain score….but don’t show the score itself on the visualization. This runtime field accounts for empty values in the first conditional. You can take this example runtime field and easily adapt to any other numeric field. You also could add multiple categories and expose this field as a keyword field.
//Return a 1 when there is a specific value
if (doc['record_score'].size()==0) {
emit(0);
} else {
if (doc['record_score'].value > 0.5 ) {
emit(1);
} else {
emit(0);
}
}Elastic Runtime field examples from LeeDr
Parse specific value from a list
A field named `gh_labels.keyword` contains a list of text values.
For example: `pending_on_dev, kibana, Team:Control Plane/Ingress, cloud, assigned, closed:support, assign::cloud-dev`
But I want to do charts based on the `Team`. The steps are to create this “team” field as a keyword type;
1. check to make sure each doc contains the field
2. check that the field isn’t empty
3. check that the size isn’t 0 (this is probably redundant)
4. set variable labels equal to the value of the field
5. for each label, if it contains the string “Team:”, emit that string. In my case I want to strip “Team:” off so I get the substring starting at position 5. Return so we don’t spend any time comparing other strings in the list.
if (doc.containsKey('gh_labels.keyword')) {
if (!(doc['gh_labels.keyword'].empty)) {
if (!(doc['gh_labels.keyword'].size() == 0)) {
def labels = doc['gh_labels.keyword'];
for (int i = 0; i < labels.length; i++) {
if (labels[i].contains("Team:")) {
emit(labels[i].substring(5));
return;
}
}
}
}
}Elastic runtime field examples from Tre’ Seymour
Creating field that detects low test coverage of code called low_coverage
An easy way to see if code test-coverage is low for a given file.
def lines = doc["lines.total"].value;
def covered = doc["lines.covered"].value;
def threshold = lines / 2;
if (covered > threshold) {
emit(false);
} else {
emit(true);
}